serverless-instagram-crawler
this is instagram hashtag crawler with serverless framework.
Config
you have to config like this. ( before deploy )
yarn run config
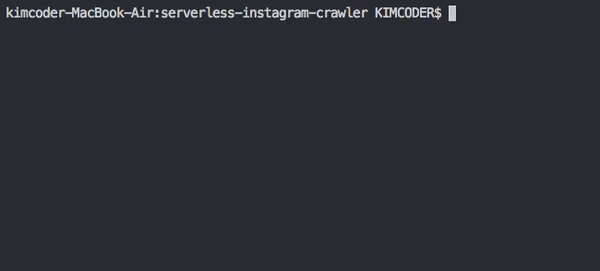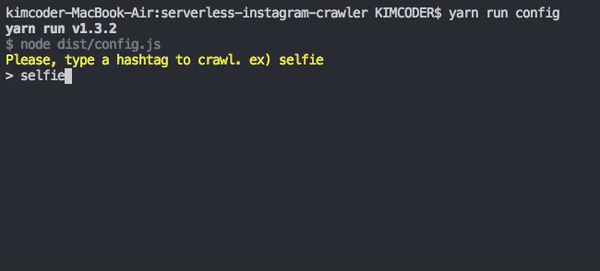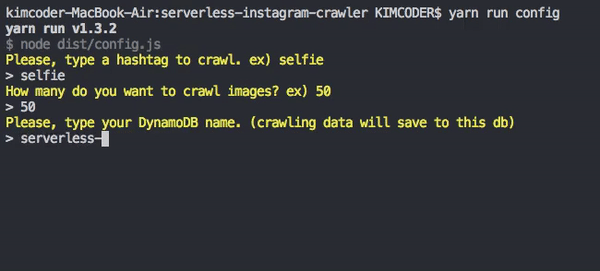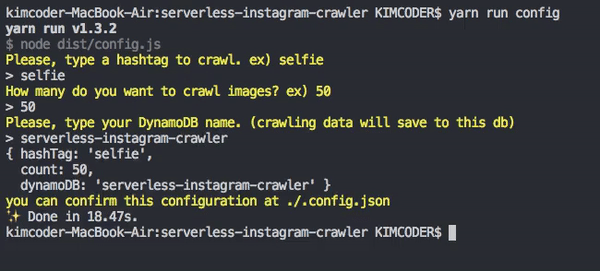
If you do config, will save a file .config.json
Serverless
Get environment variables from .config.json file
provider:
environment:
HASH_TAG: ${file(./.config.json):hashTag}
COUNT: ${file(./.config.json):count}
DYNAMODB_TABLE: ${file(./.config.json):dynamoDB}
also, lambda function has set schedule & timeout like this
it means that function will run every midnight (12:00)
functions:
crawling:
..
..
timeout: 180
events:
- schedule: cron(0 12 * * ? *)
scripts
yarn run config
yarn run test
sls deploy
directory structure
.
├── dist/ # compiled source dir ( .js )
├── src/ # source dir ( .ts )
└── test/ # test source ( .js )