Serverless Analytics ⚡️
Example project and proof of concept for a personal serverless Google Analytics clone to track website visitors. You can read more about Serverless Analytics with Amazon Kinesis and AWS Lambda on sbstjn.com …
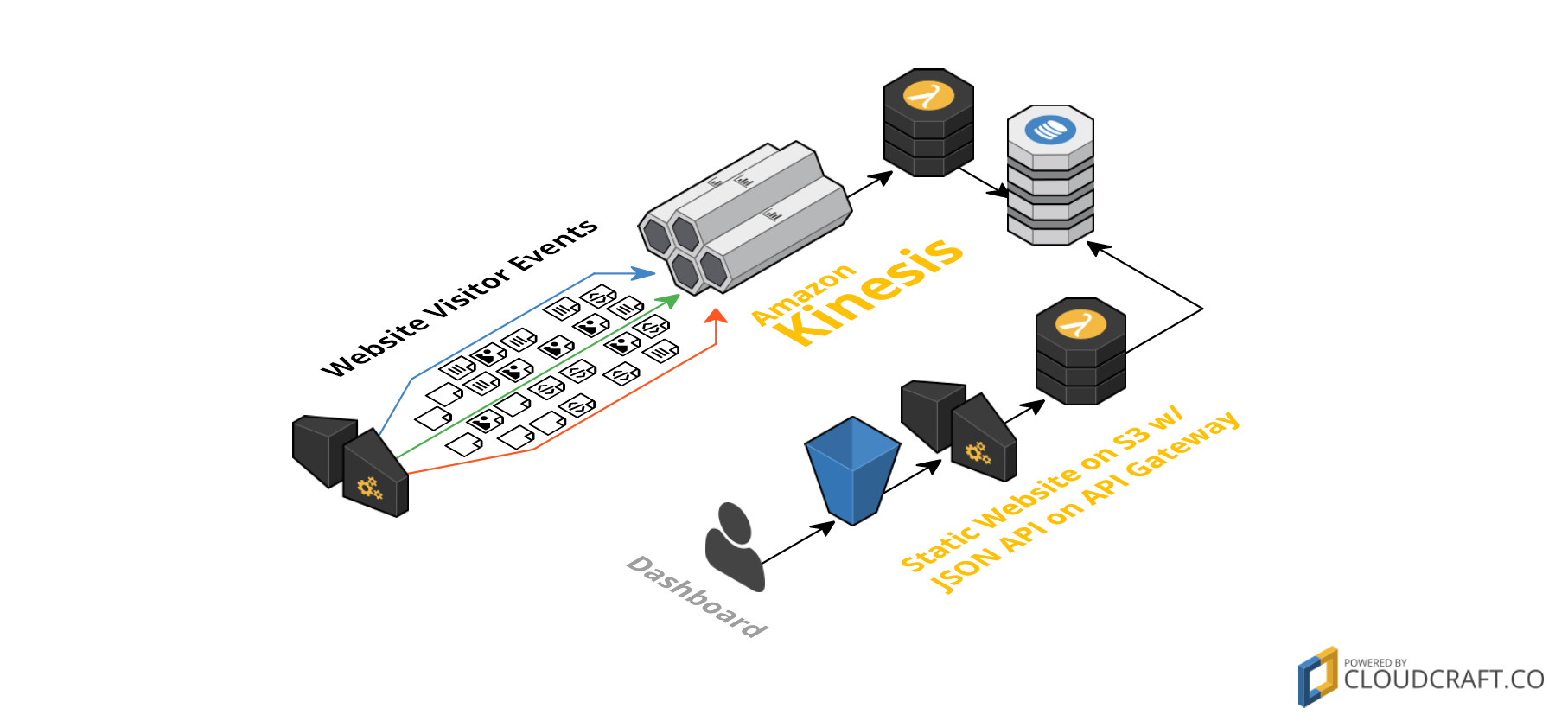
Components
After deploying the service you will have an HTTP endpoint using Amazon API Gateway that accepts requests and puts them into a Kinesis Stream. A Lambda function processes the stream and writes basic metrics about how many visitors you have per absolute URL to DynamoDB.
To access the tracked data, a basic dashboard with a JSON API is included as well. This should be a perfect starting point for you to create your own analytics service.
Tracking Service
- Amazon Kinesis to stream visitor events
- Amazon API Gateway for Kinesis HTTP proxy
- Amazon DynamoDB for data storage
- AWS Lambda to process visitor events
Dashboard
- Amazon API Gateway for JSON API
- Dashboard w/ API to show metrics
Example
The use of two API Gateways (data tracking and reading) is intended. You might have different settings for tracking and data access when you build something meaningful out of this example.
Configuration
All settings can be customized in the serverless.yml configuration file. You can easily change the DynamoDB Table, Kinesis Stream and API Gateway tracking resource name:
service: sls-analytics
custom:
names:
bucket:
website: ${self:service}-website-example
dashboard: ${self:service}-website-dashboard
resource: track
dynamodb: ${self:service}-data
kinesis: ${self:service}-stream
The S3 Bucket configuration is only needed for the included example website and dashboard. If you don't need the examples, have a look at the scripts/deploy.sh file and disable the deployment and remove the CloudFormation resources from the serverless.yml file.
Amazon requires unique names for S3 buckets and other resources. Please rename at least the service before you try to deploy the example!
Deployment
s3sync requires you to set AWS access keys as environmental variables.
AWS_ACCESS_KEY=abc123
AWS_SECRET_KEY=def456
Deploy script uses jq to read variables from generated output during deployment process. If you don't have jq installed, download it here.
Running yarn deploy will trigger a serverless deployment. After the output of your CloudFormation Stack is available, the included static websites will be generated (using the hostname from the stack output) and uploaded to the configured S3 buckets. As the last step, the deploy process will display the URLs of the example website and dashboard:
# Install dependencies
$ > yarn install
# Deploy
$ > yarn deploy
[…]
Dashboard: http://sls-analytics-dashboard.s3-website-us-east-1.amazonaws.com/
Website: http://sls-analytics-website.s3-website-us-east-1.amazonaws.com/
The website includes a simple HTML file, some stylings, and a few JavaScript lines that send a request to the tracking API on every page load. Open the URL in a web browser, hit a few times the refresh button and take a look at the DynamoDB table or the dashboard URL.
Tracking
Basically, tracking is nothing more than sending a HTTP request to the API with a set of payload information (currently url, date, name, and a websiteId). Normally you would have an additional non-JS fallback, like an image e.g., but a simple fetch call does the job for now:
fetch(
'https://lqwyep8qee.execute-api.us-east-1.amazonaws.com/v1/track',
{
method: "POST",
body: JSON.stringify(
{
date: new Date().getTime(),
name: document.title,
url: location.href,
website: 'yfFbTv1GslRcIkUsWpa7'
}
),
headers: new Headers({ "Content-Type": "application/json" })
}
)
Data Access
An example dashboard to access tracked data is included and deployed to S3. The URL will be displayed after the deploy task. You can access the metrics using basic curl requests as well. Just provide the website and date parameters:
Top Content
The ranking resource scans the DynamoDB for pages with the most hits on a specific date value:
$ > curl https://lqwyep8qee.execute-api.us-east-1.amazonaws.com/dev/ranking?website=yfFbTv1GslRcIkUsWpa7&date=MONTH:2017-08
[
{
"name": "Example Website - Serverless Analytics",
"url": "http://sls-analytics-website.s3-website-us-east-1.amazonaws.com/baz",
"value": 19
},
{
"name": "Example Website - Serverless Analytics",
"url": "http://sls-analytics-website.s3-website-us-east-1.amazonaws.com/",
"value": 10
},
{
"name": "Example Website - Serverless Analytics",
"url": "http://sls-analytics-website.s3-website-us-east-1.amazonaws.com/bar",
"value": 4
}
]
Requests per URL
The series resource scans the DynamoDB for data about a specific url in a given date period.
$ > curl https://lqwyep8qee.execute-api.us-east-1.amazonaws.com/dev/series?website=yfFbTv1GslRcIkUsWpa7&date=HOUR:2017-08-25T13&url=http://sls-analytics-website.s3-website-us-east-1.amazonaws.com/baz
[
{
"date": "MINUTE:2017-08-25T13:33",
"value": 1
},
{
"date": "MINUTE:2017-08-25T13:37",
"value": 1
},
{
"date": "MINUTE:2017-08-25T13:46",
"value": 14
},
{
"date": "MINUTE:2017-08-25T13:52",
"value": 1
}
]
Date Parameter
The DynamoDB stores the absolute hits number for the dimensions YEAR, MONTH, DATE, HOUR, and MINUTE per default. This may cause lots of write capacities when processing events, but with the serverless-dynamodb-autoscaling plugin DynamoDB will scale the capacities when needed.
All dates are UTC values!
Infrastructure
License
Feel free to use the code, it's released using the MIT license.
Contribution
You are welcome to contribute to this project! 😘
To make sure you have a pleasant experience, please read the code of conduct. It outlines core values and beliefs and will make working together a happier experience.