Amazon Kinesis Streams fan-out via Kinesis Analytics - made with 
Amazon Kinesis Analytics can fan-out your Kinesis Streams and avoid read throttling.
Each Kinesis Streams shard can support a maximum total data read rate of 2 MBps (max 5 transactions), and a maximum total data write rate of 1 MBps (max 1,000 records). Even if you provision enough write capacity, you are not free to connect as many consumers as you'd like, especially with AWS Lambda, because you'll easily reach the read capacity.
For example, if you have 10 shards and you push 8,000 events per second with an average size of 1KB each, you will be around 80% of your write capacity (8MBps out of 10MBps). If you connect three consumers though, you'll be trying to read around 24MBps (which is above your max read capacity of 20MBps).
You could implement the fan-out with AWS Lambda (great resource here), but you'd have to deal with API calls and retry issues yourself to avoid duplicated events across output channels.
This repository is a reference architecture to solve the fan-out problem with Kinesis Analytics, which can stream data from an input Stream to multiple output Streams (or Firehose delivery streams).
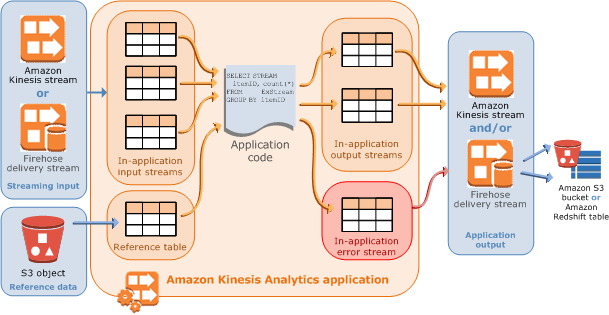
(image source: AWS Documentation)
What's the scenario?
I have chosen a sample use case based on financial transactions.
We have an input Stream where we'll be pushing fake transactions records (id, username, amount), but we want to have two Lambda consumers that will read from two independent Kinesis Streams.
One stream will contain only positive transactions (amount >= 0), and the second stream will contain only negative transactions (amount < 0).
You may want to do this to solve the read throughput problem, to further split the input stream into three or four streams, or just to simplify the processing logic and flow of each individual case.
For now, these sample Lambda Functions don't do much besides logging the batch of 100 records into CloudWatch logs.
How to deploy the Kinesis Analytics Application
First, install the Serverless Framework and configure your AWS credentials:
$ npm install serverless -g
$ serverless config credentials --provider aws --key XXX --secret YYY
Now, you can quickly install this service as follows:
$ serverless install -u https://github.com/alexcasalboni/kinesis-streams-fan-out-kinesis-analytics
The Serverless Framework will download and unzip the repository, but it won't install dependencies. Don't forget to install npm dependencies before proceeding:
$ cd kinesis-streams-fan-out-kinesis-analytics
$ npm install
Then you can deploy all the resources defined in the serverless.yml file. Unfortunately, Kinesis Analytics is not supported by CloudFormation yet, and it will be created via API as a second step.
$ sls deploy
The CloudFormation Stack will provide the following Outputs:
- TransactionsStreamARN: the input Kinesis Stream
- PositiveTransactionsStreamARN: the first output Kinesis Stream
- NegativeTransactionsStreamARN: the second output Kinesis Stream
- KinesisAnalyticsIAMRoleARN: the IAM Role required for Kinesis Analytics to read from and write into the three Kinesis Streams
You can find these values by running the following serverless command:
$ sls info --verbose
You should take note of these ARNs and use them in the following commands (ideally it shouldn't be a manual process, but this was just a 4h side project).
How to Create the Kinesis Analytics Application
This command will create the Kinesis Application:
$ npm run create -- -N kinesis-fanout-app -P {KinesisAnalyticsIAMRoleARN} -I {TransactionsStreamARN} -O {PositiveTransactionsStreamARN} -U {NegativeTransactionsStreamARN}
Don't forget to replace the resource names with the corresponding ARNs (see CloudFormation Outputs above).
How to Start/Stop the Kinesis Analytics Application
This command will start or stop the Kinesis Application, based on the current status:
$ npm run toggle -- -N kinesis-fanout-app
Hint: some intermediate status don't allow explicit transitions (e.g. "STARTING"), and you'll just have to wait :)
How to Delete the Kinesis Analytics Application
This command will delete the Kinesis Application:
$ npm run delete -- -N kinesis-fanout-app
Hint: do this only when your're done with all the other commands (Kinesis Analytics is charged per-hour).
How to Put Records into the main Kinesis Stream
This command will put a few records (up to 500) into the input Kinesis Stream:
$ npm run putrecords -- -I Transactions -N 100
Hint: this endpoint does not require a full ARN (the Stream name is enough).
Where does the magic happen?
In order to stream your records from the main Kinesis Stream to the other two, we will need a SQL query that runs on real-time data and filters/groups it based on the transaction amount.
Also, Kinesis Analytics will need to know the exact data model of the input stream. I have defined it in this file, but you can easily change the records schema and then invoke the DiscoverInputSchema API to generate the exact mapping required by Kinesis Analytics.
In case you decide to change the records structure, here are the two commands you'll need to run:
$ npm run putrecords -- -I Transactions -N 100
$ npm run discover -- -I {TransactionsStreamARN} -P {KinesisAnalyticsIAMRoleARN}
Here is the SQL query, adapted to the data model of this scenario (source file here):
CREATE OR REPLACE STREAM "POSITIVE_TRANSACTIONS" (
ID INTEGER,
USERNAME VARCHAR(200),
AMOUNT DECIMAL(5,2)
);
CREATE OR REPLACE STREAM "NEGATIVE_TRANSACTIONS" (
ID INTEGER,
USERNAME VARCHAR(200),
AMOUNT DECIMAL(5,2)
);
CREATE OR REPLACE PUMP "STREAM_PUMP1"
AS INSERT INTO "POSITIVE_TRANSACTIONS"
SELECT STREAM ID, USERNAME, AMOUNT
FROM "SOURCE_SQL_STREAM_001"
WHERE AMOUNT >= 0;
CREATE OR REPLACE PUMP "STREAM_PUMP2"
AS INSERT INTO "NEGATIVE_TRANSACTIONS"
SELECT STREAM ID, USERNAME, AMOUNT
FROM "SOURCE_SQL_STREAM_001"
WHERE AMOUNT < 0;
Ok, but what's going on?
- We define two output destinations with the very same structure, named POSITIVE_TRANSACTIONS and NEGATIVE_TRANSACTIONS, and we connect them to the corresponding Kinesis Streams (see source code here).
- We also define two "pumps" (with arbitrary names) that will buffer our data before writing into the output stream
- For each pump, we define the filtering query that will write positive transactions to the first stream, and negative transactions to the second one
Note: this SQL query will be executed in real-time on the incoming data, without any windowing or buffering. Well, in my tests it took a bit less than 2 seconds for a batch of 500 records to go through the secondary streams and reach my Lambda Functions.
Contributing
Contributors and PRs are always welcome!
Tests and coverage
Install dev dependencies with npm install --dev.