
Recently, I’ve seen a video by a really great developer and YouTuber. Its title is “Serverless Doesn’t Make Sense.” Even though I really enjoyed the video, I am not sure whether the author’s points about serverless are entirely valid, and I want to discuss them in this article.
In the introduction, the author made a joke: “There are two things in this world I don’t understand — girls and serverless.”
I don’t know about his relationship with girls, but is he right when it comes to serverless? Let’s have a look at his criticism and discuss potential contra arguments. Spoiler: I think that serverless does make sense if you know when and how to use it.
Critique of Serverless
The primary argument mentioned in the somewhat controversial YouTube video is speed. To put it more concretely, the major drawback of serverless applications from the author’s standpoint is the (well-known) cold start problem — the added latency where your code potentially cannot start execution until the underlying cloud service finishes allocating compute resources, pulling the code or container image, installing extra packages, and configuring the environment.
Engineers who prioritize execution speed above everything else give the impression that the ultimate success metric regarding the entire application lifecycle management is how fast our code can finish the task it needs to perform.
As a person who has worked in IT and seen real problems with respect to maintainability and the ability to quickly and reliably provide business value by leveraging technology, I am not sure if such a metric properly measures what matters most — the time to value, the speed of development cycles, ease of maintenance, keeping the costs low for our end users, lowering the risk of operational outages by facilitating seamless IT operations, and, finally, allocating most of our engineering time to properly solve the actual business problem rather than spending it on configuring and managing servers.
What Are Some Engineers Missing? The True Benefits of Serverless
If you care about execution speed to the point that the occasional 200 milliseconds (up to one second, according to AWS) of added latency is not acceptable in your workloads, then serverless may indeed not be an option for you, and that’s totally fine. But we should not go as far as saying that serverless doesn’t make sense because of that latency. Everyone needs to decide for themselves what latency is acceptable in their use case.
Serverless is an incredibly cost-effective and efficient way of managing IT infrastructures that is particularly beneficial for IT departments that may not have thousands of dollars to spend on idle resources and a specialized team of support engineers maintaining on-prem servers 24/7.
The low costs of serverless may outweigh any drawbacks
In most use cases I’ve seen, serverless is orders of magnitude less expensive than self-hosted resources, which is already true when only considering the actual compute costs. If you also consider that serverless significantly reduces the time needed to operate, scale, and maintain the infrastructure (the total cost of ownership ), then you will realize the true amount of cost savings. The truth is that a team of full-time engineers maintaining the infrastructure is considerably more costly than any serverless resources.
I’m not implying that serverless options are always cheaper for every use case. If you are consistently getting hundreds of millions of requests, if your workloads are very stable, and if you do have enough engineers who can monitor and scale all those resources, you may indeed be better off with your self-managed infrastructure.
The cold start is a question of configuration and budget
Coming back to the question of costs, the cold start problem these days is, to a large extent, a function of how much you are willing to spend and how you configure your serverless resources.
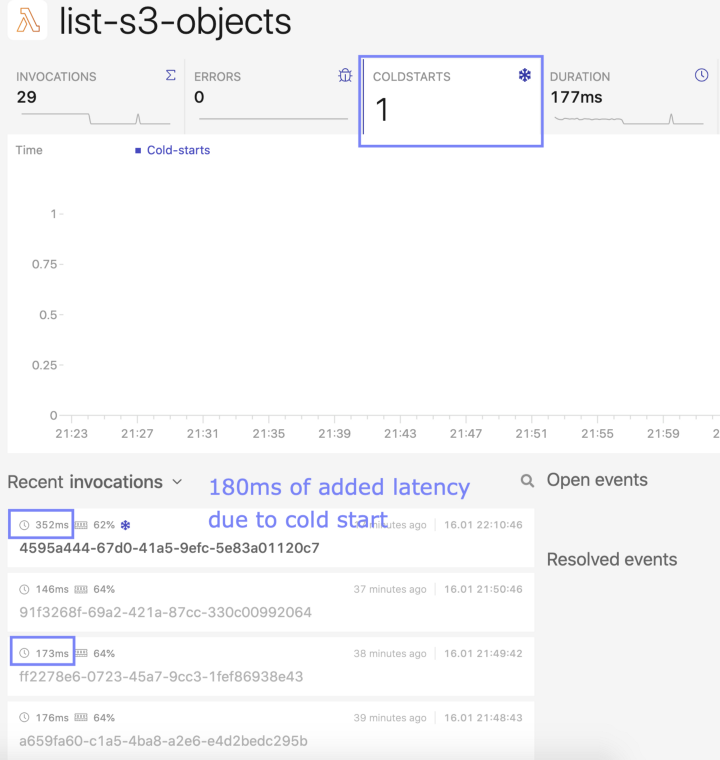
If you are willing to pay something extra, there are many ways of mitigating the cold starts, such as leveraging pre-warmed instances (provisioned concurrency) or making deliberately more requests (fake requests) to ensure that your environment stays warm. By using a monitoring platform, you can even get notified about any cold start that occurs in your functions, thus helping you to optimize your serverless resources. In the image below, you can see that among 29 invocations, we can observe one cold start, which added roughly 180 milliseconds of latency to the total execution time.
Techniques to improve the latency of your Lambda functions
You can reduce the latency of serverless functions by properly leveraging the context reuse. AWS freezes and stores Lambda’s execution context, i.e., everything that happens outside of the handler function. If another function is executed within the same 15-minutes period, the frozen environment can be reused. This means that you will get significantly better performance if you specify time-consuming operations such as connecting to a relational database outside of the Lambda handler. This article explains the topic in great detail.
There are so many fantastic articles discussing how to mitigate or even fully eliminate cold start issues, such as this one and this one. Dashbird has open-sourced a Python library called xlambda that can help you keep your Python-based Lambda functions warm. Similarly, Jeremy Daly open-sourced a similar Lambda warmer package for JavaScript. Finally, the serverless framework also includes a plugin that offers the same functionality.
What latency is acceptable by your workloads?
Eventually, it would be best if you asked yourself what latency is acceptable for your use case. When talking about latency caused by cold starts, we are usually arguing about milliseconds. In all use cases that I encountered in my job as a data engineer (also building backend APIs), the latency in day-to-day business is not noticeable.
Lastly, platforms such as the serverless Kubernetes service from AWS (also known as EKS on Fargate) allow you to mix the serverless and non-serverless data plane within a single Kubernetes cluster. This mix gives you the ability to run your mission-critical low-latency workloads on a non-serverless EC2-based data plane, while other workloads (for example, batch processing) can be served by the serverless data plane, obtaining the best of both worlds. You can find more about that in this article.
Serverless is about “NoOps” and scalability
Serverless allows you to deliver value to your business faster since the cloud provider takes care of IT operations, i.e., provisioning and scaling compute clusters, installing security patches and upgrades, and taking care of hardware crashes and memory issues. This gives you so much of your time back that you can leverage to serve your end customers better. Isn’t that what matters most in the end?
Automation behind serverless frees up the time of highly skilled engineers so they can focus on solving business problems rather than managing clusters. It allows offloading of IT operations to DevOps experts at AWS that likely have more know-how about managing computing than any other company on this planet.
Use cases that strongly benefit from serverless
Imagine that you have just founded a start-up. At first, you may not need a large cluster of resources, and you may have only a single developer. The serverless paradigm allows you to start small and automatically scale your resources as your startup grows with the pay-as-you-go cost model.
Similarly, another group that can strongly benefit from serverless is small businesses that may not have large IT departments. Being able to manage the entire application lifecycle with perhaps just a single specialized DevOps engineer (rather than an entire team of them) is a huge advantage of serverless.
If your workloads are seasonal in nature, serverless is a great option, too. For instance, if you have an e-commerce business, you likely experience seasonal peaks during Black Friday and Christmas season. A serverless infrastructure allows you to accommodate your computing to such circumstances.
Also, some events are simply unpredictable. Imagine that you have been selling hand sanitizers, disinfectants, face masks, and similar goods in your online shop. Then a global pandemic happened, and now everyone needs your products. A serverless infrastructure prepares you for any scale under any circumstances.
Code speed vs. speed of development cycles
Apart from the code execution speed, we should also consider the development speed. In many cases, the serverless microservice paradigm allows much faster development cycles since, by design, it encourages smaller individual components and lets you deploy each service independently from each other.
If serverless enables you to quickly deliver the first versions of an application to your stakeholders and iterate faster in the development cycle (while simultaneously reducing costs) then a few milliseconds of added latency due to occasional cold starts seem to be a small price to pay.
Seamless integration with other cloud services
Taking AWS as an example, each serverless service integrates with CloudWatch for logging, IAM for managing access permissions, X-Ray for collecting metrics and traces, CloudTrail for tracking audit trails, and more. In addition to that, serverless platforms usually provide you with basic building blocks to build larger, decoupled microservice architectures, such as integrating with a serverless message queue (SQS), serverless publish-subscribe message bus (SNS), serverless NoSQL data store (DynamoDB), and object storage (S3).
The Downsides of Serverless Not Considered in This YouTube Video
There are also some drawbacks that have not been mentioned in the video, and I want to list them to give you a full picture without sugarcoating anything.
Even though for many use cases, serverless seems like a paradise in terms of costs, scalability, and maintenance, it’s not a silver bullet for every use case.
- You risk vendor lock-in: The cloud providers make their services so convenient to use and cost-effective that you inherently risk being locked into their specific platform.
- When comparing serverless to self-hosted resources, you have, to a certain degree, less control over the compute resources. For instance, you cannot SSH to the underlying compute instances to perform some configuration manually, and you also have less freedom with respect to the instance type. For instance, you cannot run your serverless functions or containers on compute instances with GPUs (for now).
- Even though splitting your IT infrastructure into self-contained microservices helps manage dependencies and allows for faster release cycles, it brings another challenge regarding the management of all moving parts. While monitoring solutions solve this particular problem to a large extent, you need to be aware of the trade-offs.
Conclusion on the Critique of Serverless
Overall, it often becomes problematic when we want to use new paradigms such as serverless or cloud services in the same way we used to build self-hosted, on-prem technologies — it’s simply not the best way of approaching it. By following the lift-and-shift principle when moving your workloads to the cloud, you lose many benefits of the cloud services or even misinterpret their purpose. There is no one-size-fits-all solution because we cannot expect any technology to be usable for all use cases, be the fastest in the world, and cost close to nothing without having some downsides (such as occasional cold starts).
From my perspective, we should not talk about serverless (or frankly, about anything IT-related) by only considering a single aspect without examining other crucial aspects, especially those that have been fundamental in the design of the respective technology. In that sense, serverless does make sense if you know when and how to use it.