
Overview
As you continue to develop serverless applications, their complexity and scope can start to grow. That growth brings a need to follow structured practices to deploy your applications in a way that minimizes bugs, maintains application security, and allows you to develop more rapidly. This post will review a variety of serverless deployment best practices listed below. As we review them, I'll also show you how you can use the new Serverless Dashboard Safeguards to help you easily implement these practices in your own Serverless Framework applications. If you're not yet familiar with the Serverless Dashboard take a look at the documentation to get started.
So let's take a look at a few deployment best practices that you can implement in your own serverless applications!
Security
Properly Handling Secrets
API Keys, database credentials, or other secrets need to be securely stored and accessed by your applications. There are a few different parts to this, but some of the most critical include:
- Keeping your secrets out of your source control
- Limiting access to secrets (the Principle of Least Privilege)
- Using separate secrets for different application stages when appropriate
We've previously discussed several methods for handling secrets when using the Serverless Framework that might be good options for you.
More recently, we've also added Parameters to allow you to configure your secrets across different services, AWS accounts, and application stages. You can also use Safeguard polices to block service deployments whenever there are plaintext secrets set as environment variables in your serverless.yml.
Limiting Permissive IAM Policies
Another important best practice is to try to limit the scope of permissions that you grant to your applications. In the case of AWS, whenever you create IAM policies for your services you should limit those roles to the minimum permissions required to operate. As part of this, you should try to reduce the use of wildcards (the * character) in your policy definitions. And guess what? You can also use a Safeguard policy to block deployments that contain wildcards in IAM permissions:
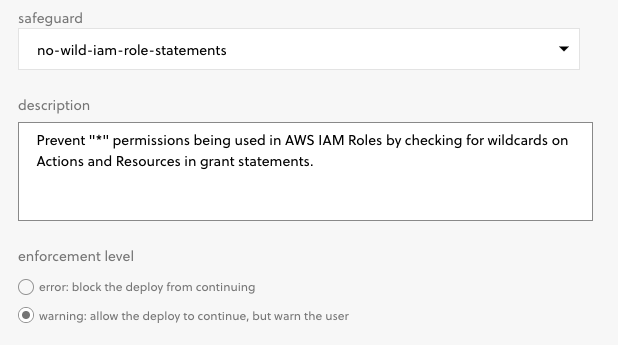
You can use this policy to either block a deployment entirely or to warn developers to take another look at the IAM polices they're using.
Restricting Deploy Times
Imagine you're an ecommerce team going into your annual Black Friday rush. You're confident in the state of your code as it is but you'd like to limit even the hint of a possibility that a new bug is introduced during the busy season. One common way to do this is to lock down your deployments during that period. Something similar happens at organizations that really don't want to get on-call notifications on weekends so they may lock down deployments between Friday and Monday morning.

While these situations might not apply to your organization, if they do (you guessed it!) there is a Safeguard that will allow you to apply this policy to your environment.
Consistent Conventions
Stages
Conventions rock. They help developers learn a set of standards and then intuitively understand other parts of a system. One of the most ubiquitous development conventions is having a separate place for code customers see (production) and one or more places for code that developers are working on that isn't quite ready (development/testing etc.). These different places are usually called stages and they allow you to set up a consistent path for your code to take as it moves towards customers.
With the Serverless Framework, by default, your applications are pushed out in a dev stage as you work on them. Then, when ready for production you can deploy them to a stage like prod by updating your serverless.yml or running a deploy command with the --stage prod option. For each of these stages, you might want to use a very different set of configuration.
Fortunately, there's a lot of new granularity to what you can do with the Serverless Dashboard when it comes to interacting with stages. Per-stage configuration can include things like:
- What AWS account or region stages are deployed to
- What Safeguards are evaluated against the deployment
- What parameters and secrets are used
This allows you to use Safeguards to do things ranging from blocking dev stage deployments to the production AWS account or making sure that your production API keys are always bundled in with production deployments. These options become very flexible to help you support the needs and workflows of your organization.
Allowed Regions
When working on a geographically distributed team, the default AWS region for each developer may not be the same. A developer in Seattle might default to us-west-2 and one in Philadelphia might use us-east-1. As you start to deploy and develop independently, these differences can lead to inadvertent issues in your code. One service may reference one region, but actually need to be deployed in another. Or, different regions may have different supported features or limitations.
To avoid issues like this, you can require developers to use a single region or a subset of regions that suit your needs. And of course... There's a Safeguard to do just that. At deployment time it ensures that your services are only deployed to a particular region or list of regions you specify:

Function Naming and Descriptions
In combination with stage and region controls, maintaining consistent naming and descriptions in your infrastructure can help new developers quickly see what services do, how they are connected to different application stages and allow them to more easily build and debug them.
One common pattern would be to require that your Lambda functions all consistently have the service name, stage, and function inside of each function name. This allows you to more easily find the relevant functions if they are in the same AWS account, and to more quickly tie multiple functions with a particular service.
Let's imagine a service that processes content submissions from users, records them in a database, and indexes them for search. It might have one Lambda function to accept/reject the submission and store it in a DynamoDB table and another to index the new data in ElasticSearch. If you take this simple architecture and spread it across a prod or dev environment you've already got four Lambda functions to keep track of. Doing this becomes easier when we follow a Lambda function naming convention like this: serviceName-stage-functionName.
Then, the function names become something like this:
newSubmissions-prod-submissionGradernewSubmissions-prod-elasticsearchIndexernewSubmissions-dev-submissionGradernewSubmissions-dev-elasticsearchIndexer
This way, you know exactly what the function you need is called and can find it when you need it. Now, if you don't want to worry about a new developer deciding to deploy an opaquely-named service, you can also enforce this naming convention using yet another Safeguard in the Serverless Dashboard.
Takeaways
This is just a subset of best practices that we want to enable in the Serverless Dashboard. There are also many other Safeguards to enable more application-specific practices like enforcing the creation of Dead Letter Queues or requiring services be within a VPC.
Keep in mind that these best practice aren't only applicable to the Serverless Framework. However you decide to build your applications, many of these practices can help you do so more effectively and securely.
Are there other development best practices you think we missed? Let us know in the comments! We're constantly looking for ways to improve the development experience for our users.