
Zero configuration, anomaly detection
The Serverless Framework makes it super easy to identify problems with your deployed serverless applications before they impact the quality of your service. When you deploy a service using the Serverless Framework your functions are automatically instrumented to detect anomalies and generate alerts.
Screen shot: alerts feed & details tab - new error identified  One of the greatest benefits of serverless architecture is that many of the things that could go wrong with our apps are no longer applicable. We generally no longer have to maintain VMs, storage, or any persisted resources. There is a lot less to monitor! However, there are still things that can go wrong and we still need to keep an eye on them.
One of the greatest benefits of serverless architecture is that many of the things that could go wrong with our apps are no longer applicable. We generally no longer have to maintain VMs, storage, or any persisted resources. There is a lot less to monitor! However, there are still things that can go wrong and we still need to keep an eye on them.
We’ve identified the most important things to monitor in your serverless applications and included, out-of-the-box, the charts, alerts and notifications you’ll need to efficiently and effectively develop and operate your serverless applications
Memory usage & duration
There are two configurable settings for each function in a serverless application, memory and timeout, that can directly impact quality of service. The memory setting controls how much memory is allocated for each invocation. The timeout setting controls the amount of time given to the invocation. If a function’s memory usage or duration exceeds those limits, the function invocation is terminated before it completes its job. As such, we want to make sure we keep an eye on memory usage and durations, and the Serverless Framework will alert you if your functions are approaching either of these limits.
Errors
Bugs happen! Our code has the most direct impact on the quality of service. We do our best to catch bugs with automated tests and pre-production releases, but it is never foolproof. But, now, the Serverless Framework has got your back. It watches for both new errors and unexpected error rates, alerts you when they occur, and provides you with the stack traces and logs you’ll need to figure out what happened.
Invocations
Lastly, we want to keep an eye on the incoming traffic. In general traffic spikes should have minimal impact on the quality of service of the functions as they will automatically scale. However, there are a few cases to consider. A spike could be the result of recursive loop or a DDoS attack. Even legitimate spikes need to be introspected. A spike in traffic can lead to more cold starts, so a lot of API requests may see much slower than usual responses. We also have to consider the down-stream impact of a spike. If our services have dependencies on third party APIs or statically provisioned resources (e.g. RDS) the dependent services may not be able to handle the request load.
The Serverless Framework keeps an eye on memory usage, durations, errors and invocations for you. When you deploy your service, the Serverless Framework will automatically instrument your service and start monitoring it right away.
Enabling these alerts couldn’t be easier. Just run serverless to start a new project or to update an existing project to work with the new alerts feature. You don’t have to instrument your code as it is done automatically when you deploy. You can learn more about installing & configuring alerts in the docs.
The full list and details of each of the alerts is available in the docs; however, here is a summary of all of the alerts available to you out of the box:
- Duration: Approaching timeout, Timeout, Unusual function duration
- Memory: Approaching out of memory, Out of memory, Unused memory
- Invocations: Escalated invocations
- Errors: New error type identified, Unusual error rate
All of these alerts are listed in the alerts tab of the service instance view in your dashboard. Each alert details page is customized for each type of alert so you get all the necessary details specific to that alert. For example, the “approaching timeout” alert shows you a graph of the durations over the past hour, stats about the duration, and suggested steps to resolve the issue.
Screen shot: alerts feed & details tab - approaching timeout alert  Of course, you aren’t going to be sitting around waiting for a notification in the dashboard. So we also have support for notifications via Slack and email. If you want to send it to something other than Slack or email, it also supports SNS Topics and Webhooks, so you can add your own custom integrations.
Of course, you aren’t going to be sitting around waiting for a notification in the dashboard. So we also have support for notifications via Slack and email. If you want to send it to something other than Slack or email, it also supports SNS Topics and Webhooks, so you can add your own custom integrations.
You can add as many notifications as you’d like to your application. Each notification can be scoped by application, service, stage or alert type and each alert is crafted by us to minimize noise. This way you’ll get alerted on only what is relevant to you.
Screen shot: notification settings 
As an example here is what a Slack notification looks like for a new error type identified alert. It gives you just enough information to be dangerous, and you can follow the link to get more details in the dashboard.
Screen shot: Slack notification 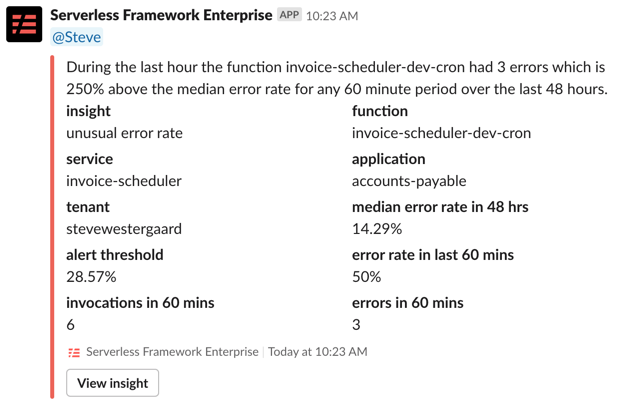 The Serverless Framework provides a powerful, unified experience to develop, deploy, test, secure, and monitor your Serverless applications. Learn more or just get started for free.
The Serverless Framework provides a powerful, unified experience to develop, deploy, test, secure, and monitor your Serverless applications. Learn more or just get started for free.