This guide is meant to help you get quickly up and running with a deployed REST API you could use for an application you are developing. We won't be going deep into the details behind why we are doing what we are doing; this guide is meant to help you get this API up and running so you can see the value of Serverless as fast as possible and decide from there where you want to go next. We will provide links to more details where appropriate if you want to dive deeper into specific topics.
You can download this project on Github.
Create an AWS account
The first thing we need to accomplish is to have somewhere to deploy to. Serverless development relies on Cloud vendors to help get your applications onto the web as fast as possible and the most widely used vendor for this is AWS.
If you already have a verified AWS account you can use, then please skip ahead. Otherwise, you will need to go to the AWS account creation page and follow the instructions for creating the account. The account will also need to be fully verified in order to be able to deploy our Serverless services.
Installing Serverless Framework
Installing the Serverless Framework is, thankfully, very easy. Since it is an NPM module, it requires Node and NPM to be installed. In case you do not have them installed, you can find details on how to do so here for your preferred platform: https://nodejs.org/en/download/
With Node and NPM installed, it is recommended to install Serverless Framework as a global module. This can be done with:
npm install -g serverless
Create a new service
In order to get started, we need to create our first service, and the Serverless Framework has a great way to help us get bootstrapped quickly and easily. In your CLI, just run the following command:
serverless
This will then start a wizard-like process to help you bootstrap a new service.
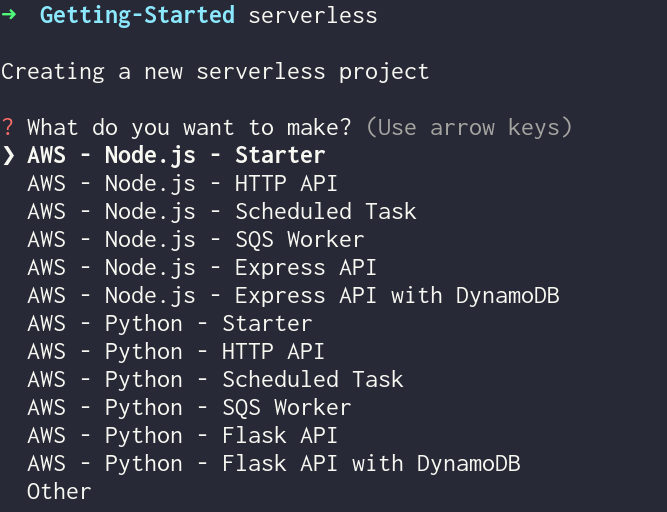
Using the “serverless” command
The first option you should see is to choose the type of template you want to base your service on. This is only to get you started and everything can be changed later if you so desire.
- For our purposes in this Getting Started, let’s choose the option “AWS - Node.js - HTTP API”.
- In the next step, feel free to name this new service whatever you wish or just press “Enter” to keep the default of aws-node-http-api-project
- This will then create a new folder with the same name as in step 2 and also pull the template related to our choice
- We are now prompted about whether we want to login or register for Serverless Dashboard.
What is Serverless Dashboard?
Serverless Dashboard is a tool provided by the Serverless Framework to help make managing connections to AWS easier, manage configuration data for your services, monitoring capabilities and the ability to read logs for your Lambda functions amongst many other features.
The dashboard is free for single developer use and we will be using it for the purpose of the getting started, because the dashboard makes it so much easier to manage connections to our AWS account for the deployment we will shortly be doing.
For all these reasons, lets choose Y (or just press Enter), to get ourselves set up with the dashboard. This will then open a window in your browser.
Let's click the “Register” link near the bottom to create our account, either using GiHub, Google or your own email address and password. Clicking register, when prompted for a username, go ahead and use a unique username that contains only numbers and lowercase letters.
Once the account is created, the CLI will then do one of two things:
- If you already have AWS credentials on your machine for some reason, you will get prompted to deploy to your AWS account using those credentials. I would recommend saying no at this point and checking out the next step “Setting up provider manually”
- If you do not have AWS credentials on your machine, the CLI will ask you if you want to set-up an “AWS Access Role” or “Local AWS Keys”. Let's choose the AWS Access Role to continue for now.

When you choose “AWS Access Role” another browser window should open (if not, the CLI provides you a link to use to open the window manually), and this is where we configure our Provider within our dashboard account.
Feel free to read through the documentation you may see, and on the next step make sure to choose the “Simple” option and then click “Connect AWS provider”. This will open a page to your AWS account titled “Quick create stack”. There is nothing we need to change here, just scroll down so that we can check the confirmation box at the bottom of the page, then click “Create Stack”.
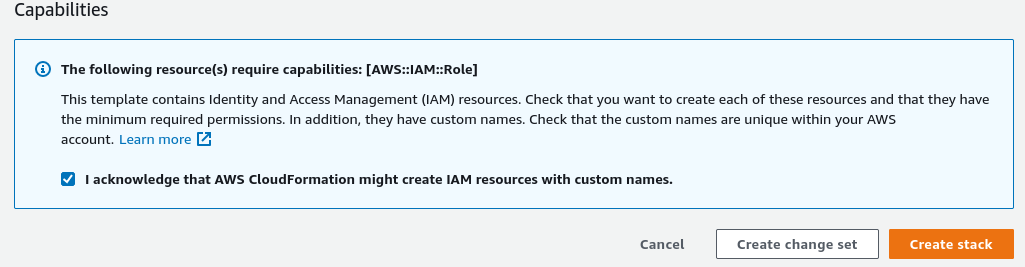
At this point we need to sit and wait a few seconds for AWS to create what’s needed, we can click the refresh button to the list on the left until the status says “CREATE_COMPLETE”.
Once that is done, you can close that tab to go back to the provider creation page on the dashboard. The dashboard should automatically detect that the provider created successfully, and so should the CLI. At this point, go ahead and reply Y to the question about deploying and we wait a few minutes for this new service to get deployed.
Setting up a provider manually
If you already had AWS credentials on your machine and chose “No” when asked if you wanted to deploy, you still need to setup a Provider. Thankfully to get one setup is pretty easy. Just go to app.serverless.com and register an account as described above. Then when you get through to the app listing page, click on “org” on the left, then choose the “providers” tab and finally “add”.
At this point adding your provider is exactly the same as described above, and once done, you can go back to your service in the CLI. Make sure to “cd” into the services folder then run “serverless deploy”. This will now use your Provider you created to deploy to your AWS account.
Using local AWS credentials
Of course, if you don’t want to set-up a provider on a dashboard account, you can use local credentials setup on your own machine. This involves creating a user with the right permissions and adding the credentials on your machine. While we won’t cover how to do that in this guide, we have some great documentation on how to accomplish this.
What have we just done?
After a successful deployment you should see, either in the dashboard or on the CLI, that you have an HTTP endpoint you can call. Also, if you open the service we just created in your favourite IDE or text editor and look at the contents of the serverless.yml, this is what controls pretty much everything in our service. You will notice a section where the functions you have are defined with events attached to them. Also take note that the code that executes when this HTTP endpoint is called is defined in the handler.js file in a function called “hello”. If you edit this file then run “serverless deploy” your changes will be pushed to your AWS account and when you next call that endpoint either in the browser or using curl, you should see your changes reflected:
curl [your endpoint address]
Create a new web API endpoint
Now that we have some basics under our belt, let’s expand this further and add some useful endpoints. It would be great to have a POST endpoint so we can add new records to a database. In order to do this we will use an AWS service called DynamoDB that makes having a datastore for Lambda functions quick and easy and very uncomplicated.
Adding a DynamoDB database
In order to do this, let’s open the serverless.yml and paste the following at the end of the file:
resources:
Resources:
CustomerTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: primary_key
AttributeType: S
BillingMode: PAY_PER_REQUEST
KeySchema:
- AttributeName: primary_key
KeyType: HASH
TableName: ${self:service}-customerTable-${sls:stage}
And lets create a new file in the same folder as the serverless.yml called createCustomer.js and add the following code to it:
'use strict'
const AWS = require('aws-sdk')
module.exports.createCustomer = async (event) => {
const body = JSON.parse(Buffer.from(event.body, 'base64').toString())
const dynamoDb = new AWS.DynamoDB.DocumentClient()
const putParams = {
TableName: process.env.DYNAMODB_CUSTOMER_TABLE,
Item: {
primary_key: body.name,
email: body.email
}
}
await dynamoDb.put(putParams).promise()
return {
statusCode: 201
}
}
You may have noticed we include an npm module to help us talk to AWS, so lets make sure we install this required npm module as a part of our service with the following command:
npm install –save aws-sdk
Note: If you would like this entire project as a reference to clone, you can find this on GitHub but just remember to add your own org and app names to the serverless.yml to connect to your Serverless Dashboard account before deploying.
Making the database table name available to the function
In order for our function to know what table to access, we need some way to make that name available and thankfully Lambda has the concept of environment variables. You can set an environment variable in your serverless.yml that is then accessible to the function in code. Under the provider section of your serverless.yml add the following:
provider:
environment:
DYNAMODB_CUSTOMER_TABLE: ${self:service}-customerTable-${sls:stage}
In our function code, you may have noticed we access this environment variable with the following: `process.env.DYNAMODB_CUSTOMER_TABLE`. Environment variables become a very powerful way to pass configuration details we need to our Lambda functions.
Setting function permissions
While we could go ahead and deploy our changes already (feel free to do so with the command “serverless deploy”), we do need to add one more thing to allow our code to talk to our database. By default, and for good security reasons, AWS requires that we add explicit permissions to allow Lambda functions to access other AWS services. This requires us adding some more configuration to our serverless.yml. Within the “provider” block of our serverless.yml, make sure you have the following:
provider:
iamRoleStatements:
- Effect: "Allow"
Action:
- "dynamodb:PutItem"
- "dynamodb:Get*"
- "dynamodb:Scan*"
- "dynamodb:UpdateItem"
- "dynamodb:DeleteItem"
Resource: arn:aws:dynamodb:${aws:region}:${aws:accountId}:table/${self:service}-customerTable-${sls:stage}
These permissions will now be applied to our Lambda function when it is deployed to allow us to connect to DynamoDB.
Adding the endpoint
We have added configuration for a database, and even written code to talk to the database, but right now there is no way to trigger that code we wrote. Time to fix that.
In your serverless.yml, paste the following block within the functions block:
provider:
iamRoleStatements:
- Effect: "Allow"
Action:
- "dynamodb:PutItem"
- "dynamodb:Get*"
- "dynamodb:Scan*"
- "dynamodb:UpdateItem"
- "dynamodb:DeleteItem"
Resource: arn:aws:dynamodb:${aws:region}:${aws:accountId}:table/${self:service}-customerTable-${sls:stage}
- The first line allows us to give our specific function a name, in this case “createCustomer”
- The next indented line defines where our code for this function lives. “createCustomer.createCustomer” is broken down as the file name preceding the period and the function name in the file after. You can specify an entire path if you prefer as well. If we moved the createCustomer.js file to another folder called “src” our handler property would be “handler: src/createCustomer.createCustomer”
- We then need to define the events that trigger our function code. You read that right, plural. We could have multiple triggers on the same code. In our case we are just using the one.
- The rest of the code is just standard HTTP configuration; calls are made to the root url “/” as a POST request.
Testing the endpoint
Now let's run “serverless deploy” and a few seconds later all the changes we deployed will now be pushed to our AWS account and the post deploy summary should provide us with the information we need about our end points.
Once we are deployed we want to test the endpoint. While you can use whichever method you prefer to test HTTP endpoints for your API, we can just quickly use curl on the CLI:
curl -X POST -d '{"name":"Gareth Mc Cumskey","email":"gareth@mccumskey.com"}' --url https://[insert your url here]/
Adding a GET endpoint
Now that we can insert data into our API lets put a quick endpoint together to retrieve all our customers. First we can insert the following function configuration into our serverless.yml
getCustomers:
handler: getCustomers.getCustomers
events:
- httpApi:
path: /
method: get
Then we need to create a file called getCustomers.js and drop the following code in for the getCustomers function.
'use strict'
const AWS = require('aws-sdk')
module.exports.getCustomers = async (event) => {
const scanParams = {
TableName: process.env.DYNAMODB_CUSTOMER_TABLE
}
const dynamodb = new AWS.DynamoDB.DocumentClient()
const result = await dynamodb.scan(scanParams).promise()
if (result.Count === 0) {
return {
statusCode: 404
}
}
return {
statusCode: 200,
body: JSON.stringify({
total: result.Count,
items: await result.Items.map(customer => {
return {
name: customer.primary_key,
email: customer.email
}
})
})
}
}
The only thing to really take note of here is the re-use of that environment variable to access the DynamoDB table and that we now use the scan method for DynamoDB to retrieve all records.
You may have noticed that in our final version of the project, we removed the default function definition and the handler.js file so go ahead and do that now if you wish.
After a “serverless deploy” we now have our brand new endpoint. And if we run a curl command against it we should get the item we inserted previously:
curl –url [insert url here]
Final thoughts
The Serverless Framework can make spinning up endpoints super quick. Everything we did could have taken you no more than 30 minutes. And now you have two endpoints that are, practically, production ready; they are fully redundant in AWS across three Availability Zones and fully load balanced. Ready to receive the traffic you want to throw at it without the associated bill of infrastructure sitting around waiting to be used.
Reach out to us on Twitter or even our community Slack workspace if you have any questions or feedback. And keep your eyes out as we release more tutorial content!