My Serverless Garden
I have a problem with my garden. Or more accurately, I have a problem remembering to care for my garden.

My name is John McKim and I'm a software developer based in Brisbane, Australia. I work for A Cloud Guru on our Serverless learning platform.
In February of this year (2016), I attended an AWS Meetup where Sam Kroonenburg spoke about A Cloud Guru. Sam told us how he built A Cloud Guru without a single server. I was inspired.
After that Meetup I started learning as much as I could about Serverless. I started by converting an Express app to Serverless with the Serverless Framework. But that wasn't enough. I wanted to build a real project. To do that, I needed a problem.
The Problem
I love gardening, but I often forget to water my plants. I needed a way to monitor my plants, and more importantly, for them to tell me when they needed watering.

This was a great problem to solve. I needed to build a dashboard and notification system and connect it to my garden through an IoT service. It's an event-driven system which makes serverless architecture an ideal solution for this problem.
The Project
The architecture for the project is below:
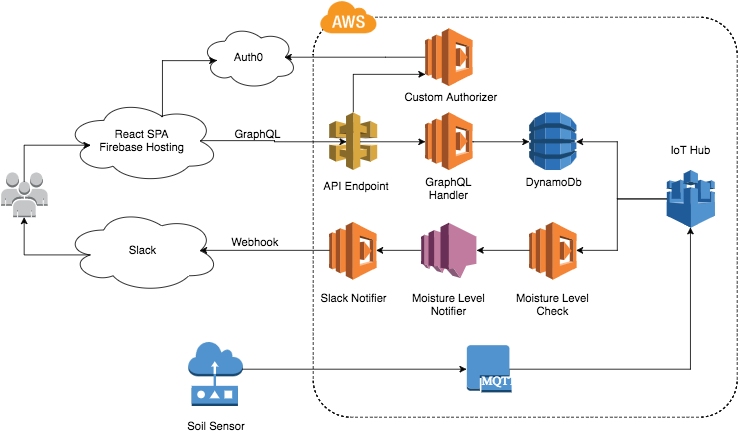
I started the project as a single monolithic Serverless service. There are good reasons to do this. As the project grew, I broke it up into four services.
IoT Service
The IoT Service is the heart of this project. The IoT Service uses the AWS IoT Device Gateway and Rules Engine. The Device Gateway provides an endpoint for messages to and from devices. I use the Rules Engine for two tasks:
- Storing raw messages in DynamoDB for the dashboard
- Invoking the check moisture Lambda in the notifications service
The Rules Engine connects the services with devices. It's the piece that makes Serverless a great solution for an IoT system.
Notifications Service
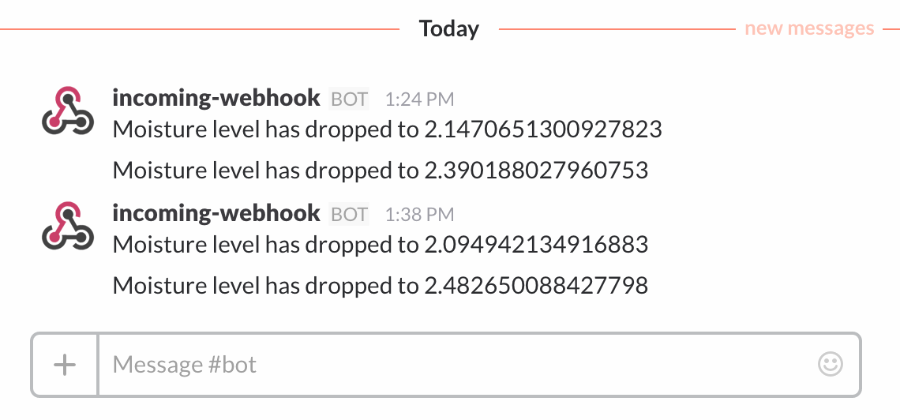
The Notifications Service sends messages to Slack when the soil moisture is too low. It has two Lambda functions in the service. The first Lambda function checks the moisture level and sends a SNS message if it's too low. The SNS message triggers the second Lambda function which sends a message to Slack. This design keeps the system highly cohesive and loosely coupled.
The end result is notifications sent from devices appearing as messages in Slack.
Web Backend
The Web Backend provides a GraphQL API for the Web Client. The backend has just one API Gateway endpoint and Lambda function. The Lambda function processes GraphQL queries and responds with data from a DynamoDB table. A custom authorizer protects the GraphQL endpoint by verifying a JWT from Auth0. This stack allowed me to create a useful backend with very few lines of code.
Web Client
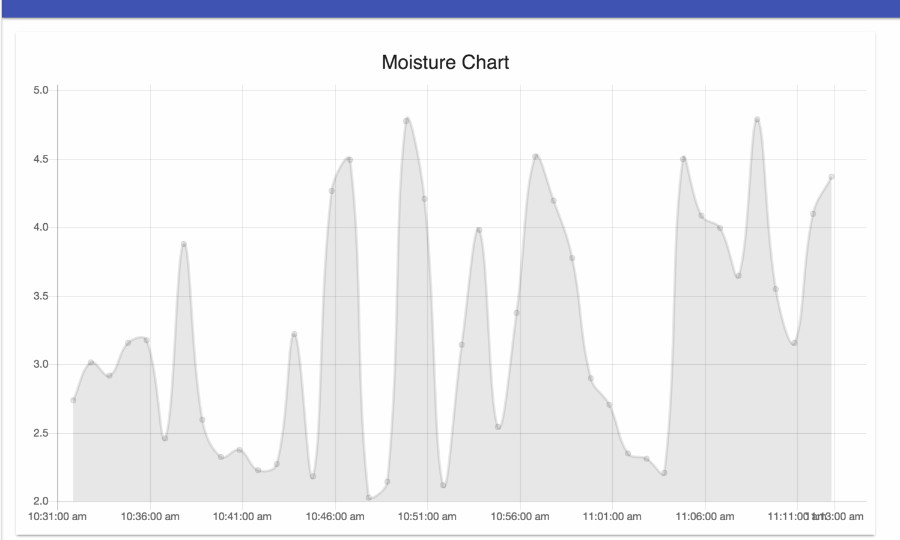
The Web Client allows me to monitor my garden through a dashboard. I built the Web Client using React + Redux. The client polls the GraphQL API every 30 seconds for moisture levels. This data is used to display a dashboard to users (me).
What I Learned
This project has been extremely valuable to me. I still forget to water my plants. But I have learned so much by building something to solve a real problem.
It wasn't all smooth sailing. In fact, the project isn't finished (is software ever finished?). The AWS IoT Device Gateway requires clients to authenticate with mutual TLS 1.2 authentication. The device I bought does not support TLS 1.2 out of the box. So as of now (Oct 2016), I haven't actually gotten a soil moisture sensor working.
Know your Services
Knowing what cloud services exist and how they work is important. If I had known that AWS IoT requires TLS 1.2 I would have bought a different device. Knowing what different services are offered allows you to choose the best in class for your project. I chose Firebase hosting over S3 + CloudFront as it's far better suited for single page apps. Spending time researching services rather than just using what you know will benefit you in the long run.
Selecting Boundaries
Selecting boundaries for Microservices is hard. A good rule of thumb for Microservices is that each service should own its own data. Right now (Oct 2016), the DynamoDB table is in the IoT service and queried by the Web Backend. I took this approach as the Rules Engine is storing the data in DynamoDB. But this breaks the earlier rule. What I should have done is create the DynamoDB table and Rule that stores the data in the Web Backend.
Automation
Investing time in unit tests and CI/CD is always worth it. This project has been deployed to AWS and Firebase countless times. But it was rarely me that deployed the project. Travis CI has saved me a lot of time and caught errors before they were a problem. Even if you are creating a small side project, help yourself by automating everything.
GraphQL
Lastly, GraphQL is awesome. It's a great alternative to REST API's and well suited to Serverless systems. If you haven't had a look at GraphQL I strongly suggest that you do. The Serverless Framework has a boilerplate that can help you get started.
What's next
I recently (Sep 2016) started working for A Cloud Guru - a company that provides online on-demand training for engineers on AWS. I'm excited to be working for the company that inspired me to learn about Serverless in the first place. I now find myself very busy running a Serverless meetup, blogging and doing talks on Serverless.
But I do hope to keep working on this project. I recently (Oct 2016) received some new devices and I hope to build the soil moisture sensor soon.
If you would like to learn more about this project please go and read my blog posts:
- Serverless Architectures— Building a Serverless system to solve a problem
- GraphQL with the Serverless Framework — Building a dashboard for my garden
- Slack Webhooks with the Serverless Framework — Building a notifications system for my garden
- AWS IoT with the Serverless Framework — Building a monitoring system for my garden
If you want see where this project goes next follow me on Medium or Twitter.